


Next: Concurrency in the Kernel
Up: Device Drivers
Previous: The Hello World Module
- While most small and medium-sized applications perform a single task from beginning to end, every kernel module just registers itself in order to serve future requests, and its initialization function terminates immediately. In other words, the task of the module's initialization function is to prepare for later invocation of the module's functions; it's as though the module were saying, "Here I am, and this is what I can do."
- The module's exit function (
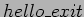 in the example) gets invoked just before the module is unloaded. It should tell the kernel, "I'm not there anymore; don't ask me to do anything else." This kind of approach to programming is similar to event-driven programming, but while not all applications are event-driven, each and every kernel module is.
in the example) gets invoked just before the module is unloaded. It should tell the kernel, "I'm not there anymore; don't ask me to do anything else." This kind of approach to programming is similar to event-driven programming, but while not all applications are event-driven, each and every kernel module is.
- Another major difference between event-driven applications and kernel code is in the exit function: whereas an application that terminates can be lazy in releasing resources or avoids clean up altogether, the exit function of a module must carefully undo everything the init function built up, or the pieces remain around until the system is rebooted.
- As a programmer, you know that an application can call functions it doesn't define: the linking stage resolves external references using the appropriate library of functions.
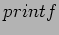 is one of those callable functions and is defined in
is one of those callable functions and is defined in  .
.
- A module, on the other hand, is linked only to the kernel, and the only functions it can call are the ones exported by the kernel; there are no libraries to link to. The
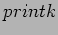 function used in
function used in 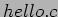 earlier, for example, is the version of defined within the kernel and exported to modules. It behaves similarly to the original function, with a few minor differences, the main one being lack of floating-point support.
earlier, for example, is the version of defined within the kernel and exported to modules. It behaves similarly to the original function, with a few minor differences, the main one being lack of floating-point support.
- Figure 1.5 shows how function calls and function pointers are used in a module to add new functionality to a running kernel.
Figure 2:
Linking a module to the kernel.
|
|
- Because no library is linked to modules, source files should never include the usual header files,
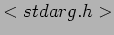 and very special situations being the only exceptions. Only functions that are actually part of the kernel itself may be used in kernel modules. Anything related to the kernel is declared in headers found in the kernel source tree you have set up and configured; most of the relevant headers live in include/linux and include/asm, but other subdirectories of include have been added to host material associated to specific kernel subsystems.
and very special situations being the only exceptions. Only functions that are actually part of the kernel itself may be used in kernel modules. Anything related to the kernel is declared in headers found in the kernel source tree you have set up and configured; most of the relevant headers live in include/linux and include/asm, but other subdirectories of include have been added to host material associated to specific kernel subsystems.
- Another important difference between kernel programming and application programming is in how each environment handles faults: whereas a segmentation fault is harmless during application development and a debugger can always be used to trace the error to the problem in the source code, a kernel fault kills the current process at least, if not the whole system.
Subsections
Next: Concurrency in the Kernel
Up: Device Drivers
Previous: The Hello World Module
Cem Ozdogan
2007-04-16
![\includegraphics[scale=1]{figures/linkingmodule.ps}](img15.png)